
· 4 min read
A UX-centric approach to navigating city council hearings with LLMs
.")
👉
This blog post discusses a prototype I worked on which is now live at https://citymeetings.nyc.
citymeetings.nyc is a tool built to help folks navigate NYC city meetings easily.
I’ve been using LLMs to glean information from NYC city council meetings as part of my work writing this newsletter on NYC city council activity.
For a lot of this work I write prompts and pipe text from bills, memos, and transcripts into Simon Willison’s llm tool. It is incredibly handy.
Where this approach fails is when I’m using LLMs to navigate long council meetings (and, unfortunately, most council meetings are long).
My goal is to find things that are “notable” in these meetings so I can write about them. Notability is hard to define, but here are some things that might fit my criteria:
- New facts that emerge from hearings.
- Contentious exchanges between council members and a city agency.
- Surprising testimonies from entities in NYC.
- Passionate statements by council members about hot-button topics.
- Things the public does not know about, but might find interesting.
Transcripts for these meetings are regularly 40k to 100K tokens, which gpt-4-turbo’s context window fits comfortably. Unfortunately, I run into two problems:
- My output is way less useful with long contexts, which is likely due to the lost-in-the-middle problem: LLMs don’t effectively use long contexts and disproportionately weight context at the beginning and end of inputs.
- Prompts are more effective when they have the right context and clear instructions, but “notability” is hard to define and requires context around the NYC council’s workings and NYC current events.
I find myself having many conversations using the llm CLI, and then reading the raw transcript/watching the video to seek neighboring context and verify answers I get. It’s not that effective: I still have to read a lot and I have to get lucky in my quest for notable bits of info.
What I’ve really wanted for these meetings is an index that lets me browse a transcript quickly and jump to potentially high-signal segments. I want to skip procedural content, like roll calls, and jump straight to an exchange that starts with a council member’s question. Or I want to browse all the public testimonies at the end and see who showed up to the hearing and why.
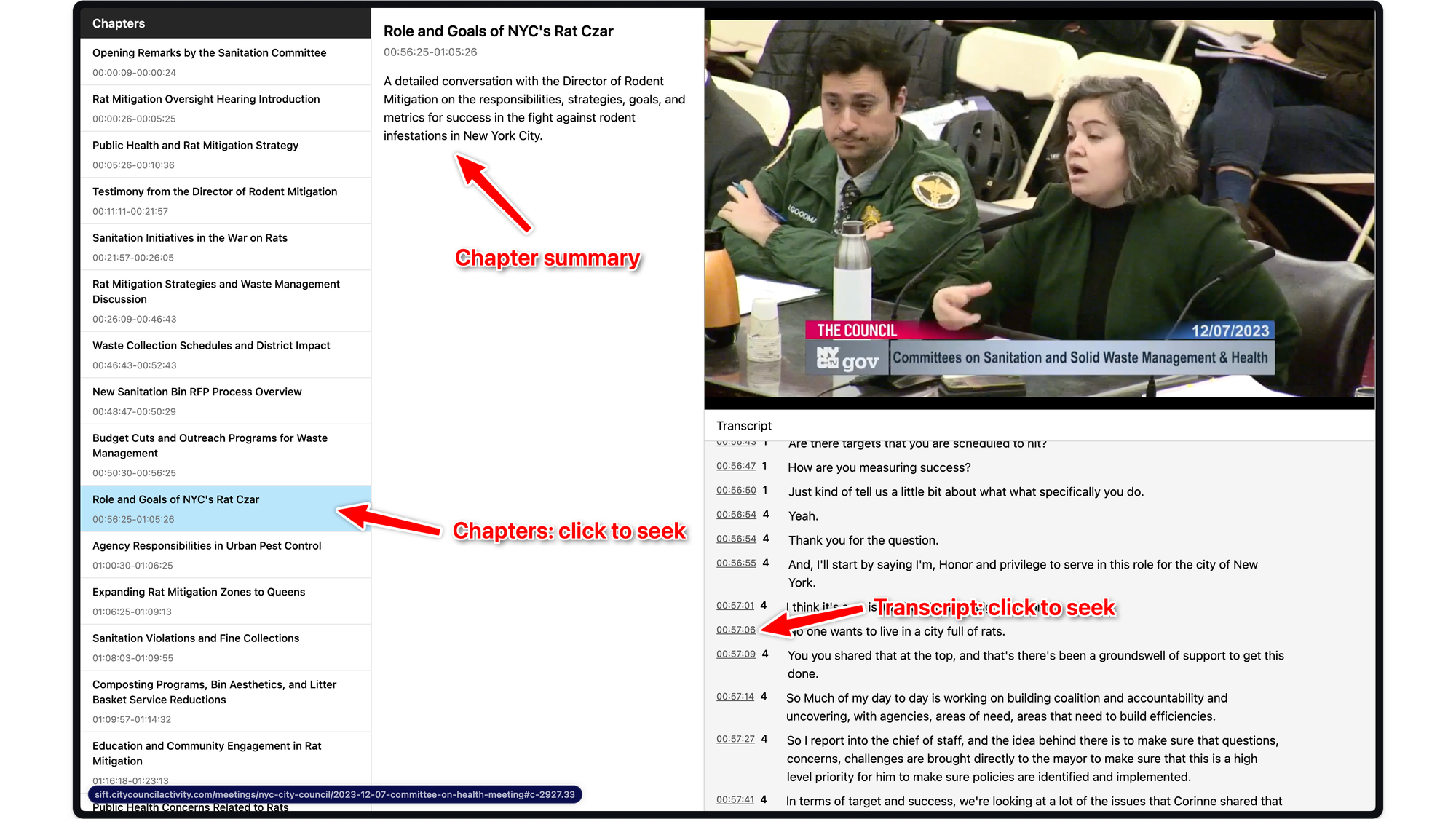
Here is a prototype that attempts this with two council meetings:
A December 7th, 2023 hearing on the rat problem in NYC.A December 20th, 2023 city council stated meeting
Visit citymeetings.nyc to use the tool.
For these, I use GPT-4 to generate chapters and I worked with my parter at Baxter to glue it together in the UI you see above.
Using this tool, I can browse chapters and click on one to seek to that point in both the video and transcript. After clicking on a chapter, I can seek in a finer-grained way by clicking on a timestamp in the transcript.
That second feature is not AI, but it’s important because it leaves a margin for error when LLMs inevitably mess up chapter boundaries. The chapters in the prototype need a lot of improvement, but this UX is still orders of magnitude better for research than:
- … piping 50K tokens into
llmand praying for something useful. - … reading a city council transcript.
- … watching a city council meeting.
I’m wildly excited about research tools using LLMs because things like this are possible now that were not possible a year ago (GPT-4 only came out 10 months ago).
I’m also excited about how these tools can be applied to repurpose virtually all audio and video content out there for personal use
Tomasz Tunguz linked to a video in today’s newsletter that I was about to watch, but I immediately bounced when I saw it was 3 hours long. I will never watch the video he linked to, but I would have spent 10 minutes browsing it using the tool I built and probably gotten what Tomasz got out of it.
I’m continuing work on this tool in service of my newsletter on city council activity and because it is gobs of fun.
I’ll be releasing it for the public when it’s ready. (Update: It is available now at citymeetings.nyc)
I’ll also be writing about specific challenges involved in things like speaker identification, improving chapter quality, extracting pull quotes, search (semantic and otherwise), and the realities of operating software like this. (Update: I gave a talk on this topic at NYC School of Data and published my annotated slides here.)